※本ブログおよび掲載記事は、Google、Amazon、楽天市場のアフィリエイト広告を利用しています。
※Amazonのアソシエイトとして日本橋浜町weblogは適格販売により収入を得ています。
はじめに
前回は、時系列データの読み込みと視覚化、そのグラフを目の子でチェックし特徴をピックアップした。
mnoguti.hatenablog.com
今回は、視覚化をさらに進め、ヒストグラムと箱ひげ図により分布の特徴を確認する。その上で、感覚で捉えていた特徴を基本統計量という定量的な指標で確認する。

使うソフトはR/RStudioだ。いつものように生成AIに壁になってもらい、自問自答?しながら進める。

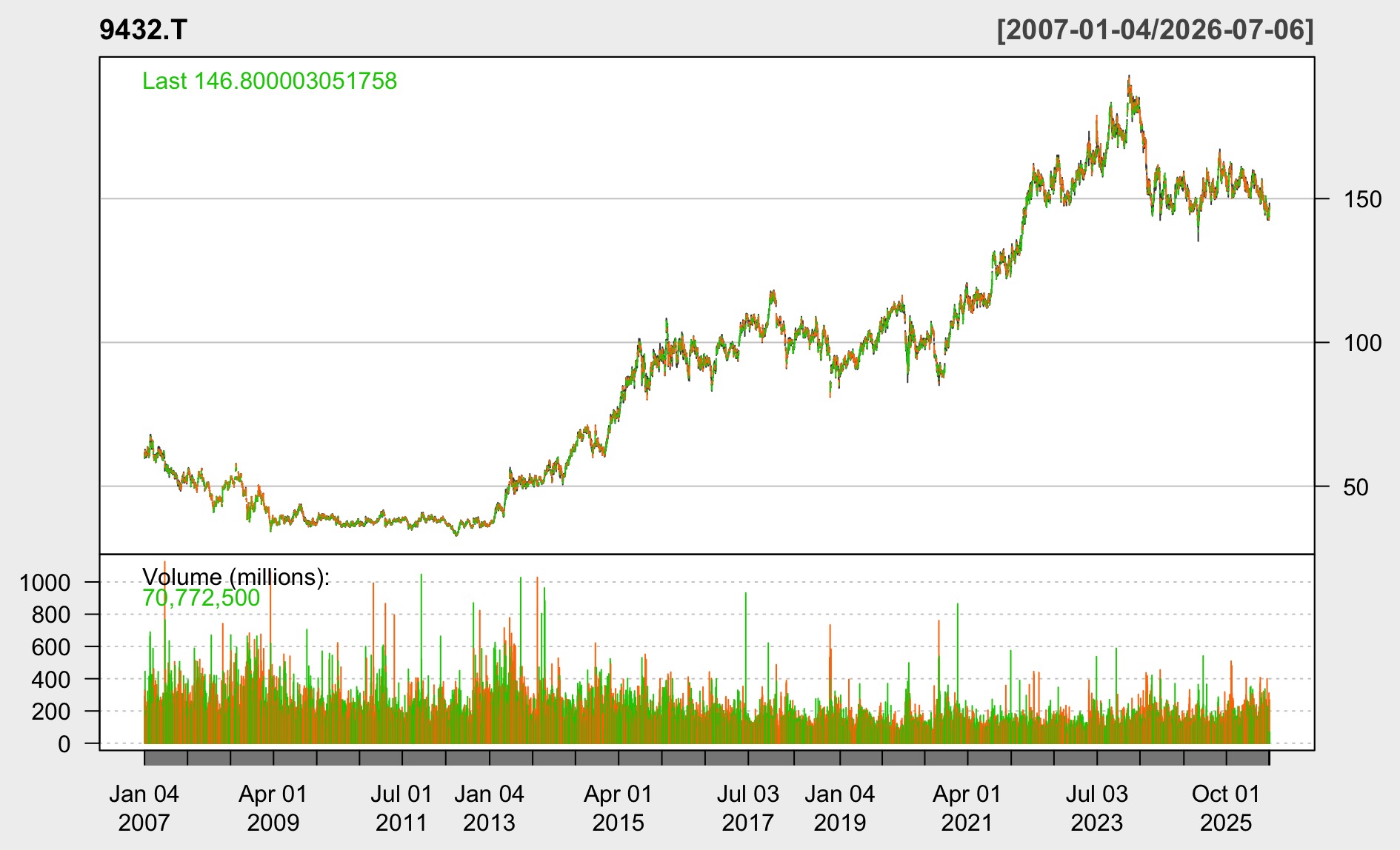
前回のグラフを再掲しよう。2007年から2026年までの日時終値(調整後)のデータだ。
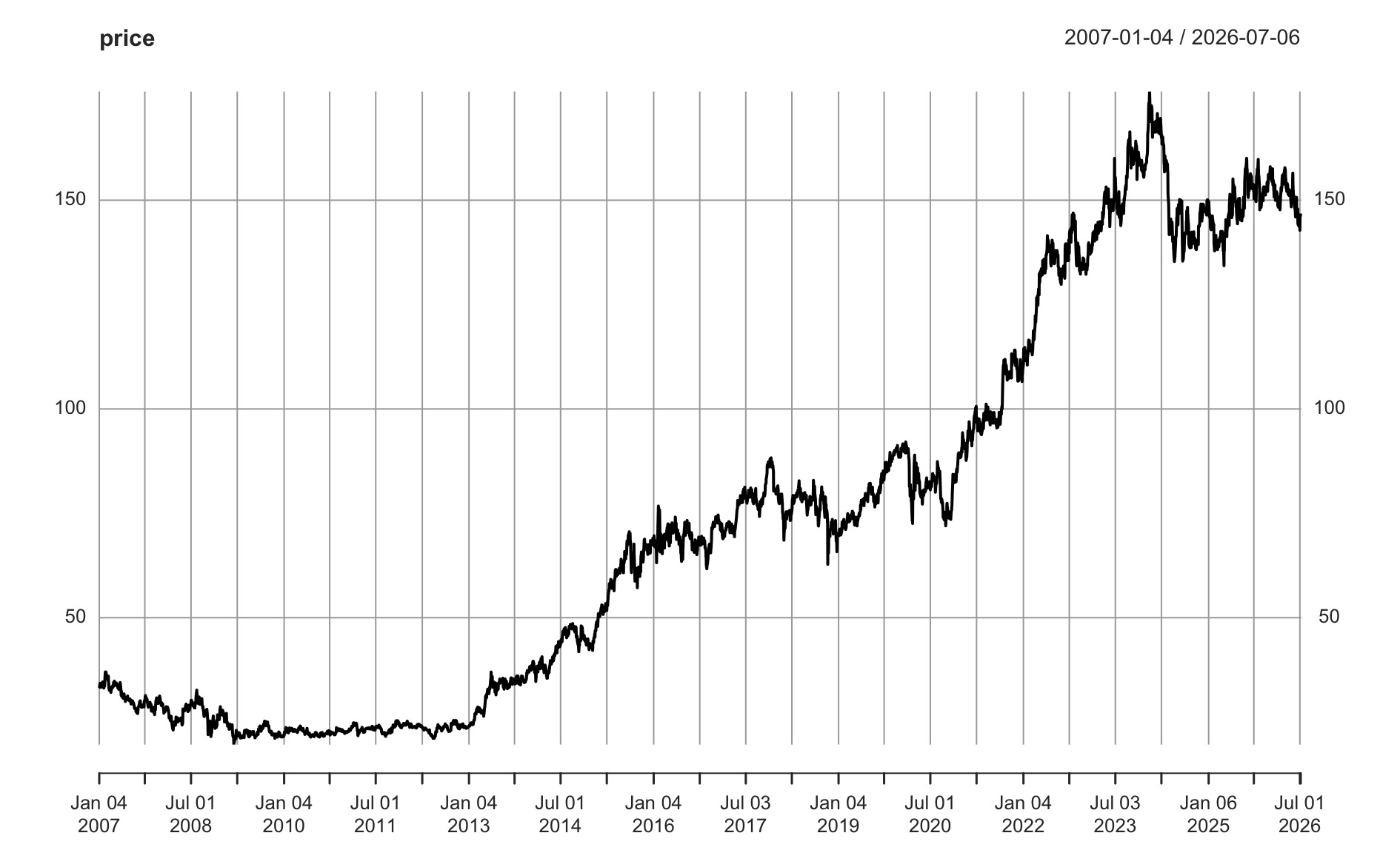
折れ線グラフは、時間方向の変化の特徴を捉える視覚化であった。この他に分布の確認、バラツキや外れ値の確認をグラフを使ってできる。
続・データの視覚化
そこで、分布の確認には、ヒストグラム、バラツキ等には箱ひげ図を描いてその特徴を確認する。

横に並べてみた。それでは各々のグラフの特徴を挙げてみる。
ヒストグラム
まずはヒストグラムを確認する。最初に目を引くのは、価格帯ごとに複数のピーク(山)が見られる点である。特に30円台、80円台、140円台付近に山が形成されており、単一の価格帯に集中しているのではなく、時期によって異なる価格水準で推移してきたことがうかがえる。
また、最も観測頻度が高いのは30円台であり、次いで80円台、140円台付近にも比較的多くのデータが分布している。これは、長期にわたる株価の推移の中で、複数の代表的な価格帯が存在したことを示している。
なお、本データは時系列データであるため、このような複数の山は価格の推移(トレンド)の影響を反映している可能性が高い。
箱ひげ図
次に箱ひげ図を確認する。中央値は約70円付近に位置している。また、第1四分位数は約30円、第3四分位数は約100円であり、中央の50%のデータはこの範囲に分布している。
外れ値は観測されておらず、極端に離れた株価は存在しないことが分かる。また、箱より上側のひげの方がやや長いことから、高価格帯までデータが広がっている様子が読み取れる。
時系列データでヒストグラムと箱ひげ図を確認する際の注意点
繰り返しになるが、今回のヒストグラムの「3つの山」は、統計学では混合分布(mixture distribution)のような形にも見えるが、このケースでは「異なる時期の株価水準が重なった結果」と説明するのが最も自然だ。
ヒストグラムと箱ひげ図は、いずれも時間の情報を無視してデータ全体の分布を確認するグラフである。そのため、時系列データではトレンドの影響を受けた分布になることがある。時間方向の特徴を理解するためには、時系列グラフとあわせて確認することが重要である。
基本統計量の確認
次に基本統計量の確認だ*1。ここでは、サンプルサイズ、最大・最小値、範囲、平均値、中央値、分散・標準偏差、四分位数・四分位範囲、変動係数を確認する。
サンプルサイズ
前回の記事にも書いた通り、データ期間は、2007年1月4日から2026年7月6日までの取引日のデータになる。サンプルサイズは、4790個となった。約19年半にわたる日次データであることから、長期的なトレンドや自己相関など、時系列データの特徴を分析するには十分なデータ量である。
最大値・最小値・範囲
最大値は、176.0321円。最小値は、19.59897円。データ範囲は、156.4331円となる。分析期間中に株価は約9倍の価格帯を経験している。また、データ範囲から長期間にわたって株価水準が大きく変化してきたことが分かる。このことは、長期トレンドの存在を示唆している。
平均値・中央値
平均値は、73.20743円で、中央値69.95619円をわずかに上回っている。両者の差は大きくないことから、全体として極端に歪んだ分布ではないと考えられる。一方で、平均値が中央値を上回ることから、高価格帯のデータが平均値を押し上げている可能性も示唆される。
分散・標準偏差
分散は、2163.684。標準偏差は、46.51541。標準偏差は46.52円であり、平均株価(73.21円)と比較すると比較的大きい値となっている。これは、分析期間中の株価変動が大きく、価格のばらつきが大きいことを示している。
四分位数・四分位範囲
四分位数は以下の通り。
- 最小値:19.60
- 第一四分位数:28.01
- 中央値:69.96
- 平均値:73.21
- 第三4分位数:99.48
- 最大値:176.03
四分位範囲(IQR)は、71.47671となる。
第1四分位数は28.01円、第3四分位数は99.48円であり、データの中央50%はこの範囲に分布している。また、四分位範囲(IQR)は71.48円と比較的大きく、株価の分布には相応のばらつきが存在することが分かる。一方、箱ひげ図では顕著な外れ値は確認されていない。
変動係数
変動係数は、0.635392。この統計量は平均値に対する相対的なばらつきを表す指標であり、本データでは平均株価の約64%に相当する変動が存在することを意味する。この結果から、分析期間を通じて株価は比較的大きく変動していたことが分かる。
一応のまとめ
今回の分析では、グラフによる視覚化と基本統計量の両面からNTT株価の特徴を確認した。時系列グラフからは長期的な価格上昇が見られ、ヒストグラムや箱ひげ図からは株価が複数の価格帯に分布し、比較的大きなばらつきを持つことが分かった。また、基本統計量では標準偏差や変動係数が比較的大きく、分析期間を通じて株価が大きく変動してきたことが確認できた。
記述統計によって『どのようなデータなのか』は把握できた。しかし、『時間とともにどのように変化しているのか』は、時系列分析によって初めて明らかになる。これまでの分析だけでは、株価が時間の経過とともにどのような特徴を持って変化しているのかまでは十分に分からない。そこで次回からは、時系列データ特有の特徴であるトレンド、季節性、周期性、自己相関、定常性について順に分析し、NTT株価の時系列的な特徴を詳しく明らかにしていく。
おすすめの文献
統計学の入門書としては以下の書籍がおすすめ。
時系列分析では以下の書籍。自分はまだ読んでいない。


 220グラム (x 5)")

 新生活 仕送り 壱番屋 ココ壱 ココイチ 専門店 レトルト カレー ポーク 甘口 本格的 タイパ飯 簡単調理 常温保存 非常食")

 120g")


)")









 無香 【Amazon.co.jp限定】")

")


 アイスバッグ 首用 首 冷却 暑さ対策 ゴルフ テニス 日常生活 フリーサイズ 387000")

![国立大学教授・腰の世界的名医が教える 運動を頑張らなくても脊柱管狭窄症がよくなる1分ほぐし大全 特大版 ([バラエティ])](https://m.media-amazon.com/images/I/51rL5Fxvn0L._SL500_.jpg "国立大学教授・腰の世界的名医が教える 運動を頑張らなくても脊柱管狭窄症がよくなる1分ほぐし大全 特大版 ([バラエティ])")















![【日本業界初!28℃で自然凍結】GGPT アイス枕 氷嚢 ひんやりマット [41×30cm] 氷枕 結露なし 冷却マット 繰り返し使用可能 冷感マット 長時間 ひんやりクールシート 冷却グッズ 最強 ひんやりグッズ 冷感 枕 クール 暑さ対策グッズ 熱中症対策 アイスパック 赤ちゃん ベビーカー ペット 大人用 室内 屋外 外出 花火大会 スポーツ観戦 アウトドア 父の日 母の日 記念日 誕生日プレゼント お祝い ブルー](https://m.media-amazon.com/images/I/41DxDuYNKdL._SL500_.jpg "【日本業界初!28℃で自然凍結】GGPT アイス枕 氷嚢 ひんやりマット [41×30cm] 氷枕 結露なし 冷却マット 繰り返し使用可能 冷感マット 長時間 ひんやりクールシート 冷却グッズ 最強 ひんやりグッズ 冷感 枕 クール 暑さ対策グッズ 熱中症対策 アイスパック 赤ちゃん ベビーカー ペット 大人用 室内 屋外 外出 花火大会 スポーツ観戦 アウトドア 父の日 母の日 記念日 誕生日プレゼント お祝い ブルー")


![おいしい水 天然水 ソルティグレフル 600ml×24本 [熱中症対策][アサヒ飲料]](https://m.media-amazon.com/images/I/316H0FUqahL._SL500_.jpg "おいしい水 天然水 ソルティグレフル 600ml×24本 [熱中症対策][アサヒ飲料]")